 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCP-Atlas: A Large-Scale Benchmark for Tool-Use Competency with Real MCP Servers
Jan 31, 2026The Model Context Protocol (MCP) is rapidly becoming the standard interface for Large Language Models (LLMs) to discover and invoke external tools. However, existing evaluations often fail to capture the complexity of real-world scenarios, relying on restricted toolsets, simplistic workflows, or subjective LLM-as-a-judge metrics. We introduce MCP-Atlas, a large-scale benchmark for evaluating tool-use competency, comprising 36 real MCP servers and 220 tools. It includes 1,000 tasks designed to assess tool-use competency in realistic, multi-step workflows. Tasks use natural language prompts that avoid naming specific tools or servers, requiring agents to identify and orchestrate 3-6 tool calls across multiple servers. We score tasks using a claims-based rubric that awards partial credit based on the factual claims satisfied in the model's final answer, complemented by internal diagnostics on tool discovery, parameterization, syntax, error recovery, and efficiency. Evaluation results on frontier models reveal that top models achieve pass rates exceeding 50%, with primary failures arising from inadequate tool usage and task understanding. We release the task schema, containerized harness, and a 500-task public subset of the benchmark dataset to facilitate reproducible comparisons and advance the development of robust, tool-augmented agents.
PRBench: Large-Scale Expert Rubrics for Evaluating High-Stakes Professional Reasoning
Nov 14, 2025Frontier model progress is often measured by academic benchmarks, which offer a limited view of performance in real-world professional contexts. Existing evaluations often fail to assess open-ended, economically consequential tasks in high-stakes domains like Legal and Finance, where practical returns are paramount. To address this, we introduce Professional Reasoning Bench (PRBench), a realistic, open-ended, and difficult benchmark of real-world problems in Finance and Law. We open-source its 1,100 expert-authored tasks and 19,356 expert-curated criteria, making it, to our knowledge, the largest public, rubric-based benchmark for both legal and finance domains. We recruit 182 qualified professionals, holding JDs, CFAs, or 6+ years of experience, who contributed tasks inspired by their actual workflows. This process yields significant diversity, with tasks spanning 114 countries and 47 US jurisdictions. Our expert-curated rubrics are validated through a rigorous quality pipeline, including independent expert validation. Subsequent evaluation of 20 leading models reveals substantial room for improvement, with top scores of only 0.39 (Finance) and 0.37 (Legal) on our Hard subsets. We further catalog associated economic impacts of the prompts and analyze performance using human-annotated rubric categories. Our analysis shows that models with similar overall scores can diverge significantly on specific capabilities. Common failure modes include inaccurate judgments, a lack of process transparency and incomplete reasoning, highlighting critical gaps in their reliability for professional adoption.
Remote Labor Index: Measuring AI Automation of Remote Work
Oct 30, 2025AIs have made rapid progress on research-oriented benchmarks of knowledge and reasoning, but it remains unclear how these gains translate into economic value and automation. To measure this, we introduce the Remote Labor Index (RLI), a broadly multi-sector benchmark comprising real-world, economically valuable projects designed to evaluate end-to-end agent performance in practical settings. AI agents perform near the floor on RLI, with the highest-performing agent achieving an automation rate of 2.5%. These results help ground discussions of AI automation in empirical evidence, setting a common basis for tracking AI impacts and enabling stakeholders to proactively navigate AI-driven labor automation.
MultiNRC: A Challenging and Native Multilingual Reasoning Evaluation Benchmark for LLMs
Jul 23, 2025



Although recent Large Language Models (LLMs) have shown rapid improvement on reasoning benchmarks in English, the evaluation of such LLMs' multilingual reasoning capability across diverse languages and cultural contexts remains limited. Existing multilingual reasoning benchmarks are typically constructed by translating existing English reasoning benchmarks, biasing these benchmarks towards reasoning problems with context in English language/cultures. In this work, we introduce the Multilingual Native Reasoning Challenge (MultiNRC), a benchmark designed to assess LLMs on more than 1,000 native, linguistic and culturally grounded reasoning questions written by native speakers in French, Spanish, and Chinese. MultiNRC covers four core reasoning categories: language-specific linguistic reasoning, wordplay & riddles, cultural/tradition reasoning, and math reasoning with cultural relevance. For cultural/tradition reasoning and math reasoning with cultural relevance, we also provide English equivalent translations of the multilingual questions by manual translation from native speakers fluent in English. This set of English equivalents can provide a direct comparison of LLM reasoning capacity in other languages vs. English on the same reasoning questions. We systematically evaluate current 14 leading LLMs covering most LLM families on MultiNRC and its English equivalent set. The results show that (1) current LLMs are still not good at native multilingual reasoning, with none scoring above 50% on MultiNRC; (2) LLMs exhibit distinct strengths and weaknesses in handling linguistic, cultural, and logical reasoning tasks; (3) Most models perform substantially better in math reasoning in English compared to in original languages (+10%), indicating persistent challenges with culturally grounded knowledge.
Creating and Characterizing a Diverse Corpus of Sarcasm in Dialogue
Sep 15, 2017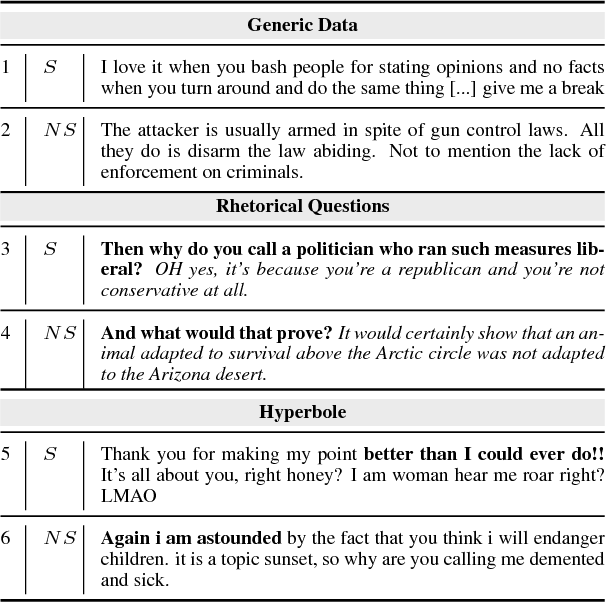

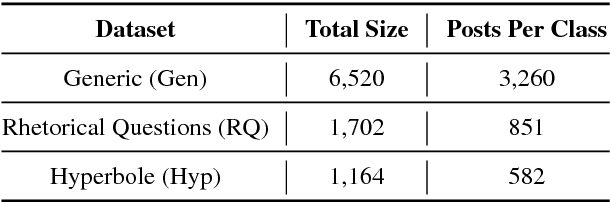
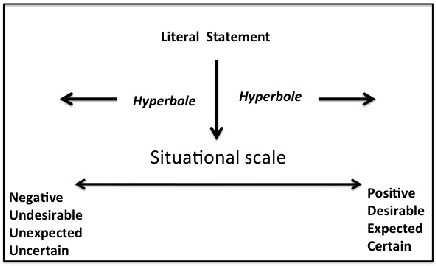
The use of irony and sarcasm in social media allows us to study them at scale for the first time. However, their diversity has made it difficult to construct a high-quality corpus of sarcasm in dialogue. Here, we describe the process of creating a large- scale, highly-diverse corpus of online debate forums dialogue, and our novel methods for operationalizing classes of sarcasm in the form of rhetorical questions and hyperbole. We show that we can use lexico-syntactic cues to reliably retrieve sarcastic utterances with high accuracy. To demonstrate the properties and quality of our corpus, we conduct supervised learning experiments with simple features, and show that we achieve both higher precision and F than previous work on sarcasm in debate forums dialogue. We apply a weakly-supervised linguistic pattern learner and qualitatively analyze the linguistic differences in each class.
Learning Fine-Grained Knowledge about Contingent Relations between Everyday Events
Aug 30, 2017
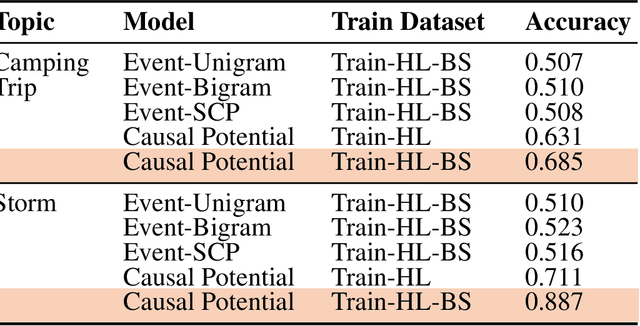
Much of the user-generated content on social media is provided by ordinary people telling stories about their daily lives. We develop and test a novel method for learning fine-grained common-sense knowledge from these stories about contingent (causal and conditional) relationships between everyday events. This type of knowledge is useful for text and story understanding, information extraction, question answering, and text summarization. We test and compare different methods for learning contingency relation, and compare what is learned from topic-sorted story collections vs. general-domain stories. Our experiments show that using topic-specific datasets enables learning finer-grained knowledge about events and results in significant improvement over the baselines. An evaluation on Amazon Mechanical Turk shows 82% of the relations between events that we learn from topic-sorted stories are judged as contingent.
* SIGDIAL 2016